Generative Adversarial Networks
This introduction includes Style Transfer, VAE, DALL-E, GAN, Image Inpainting, DeepFaceDrawing, Toonify, PoseGAN, Pose2Pose, Virtual Try On, Face Swap, Talking Head, VQ-VAE, Music Seperation, Deep Singer, Voice Conversion.
Style Transfer
DeepDream

Nerual Style Transfer
Paper: A Neural Algorithm of Artistic Style
Code: ProGamerGov/neural-style-pt
Tutorial: Neural Transfer using PyTorch

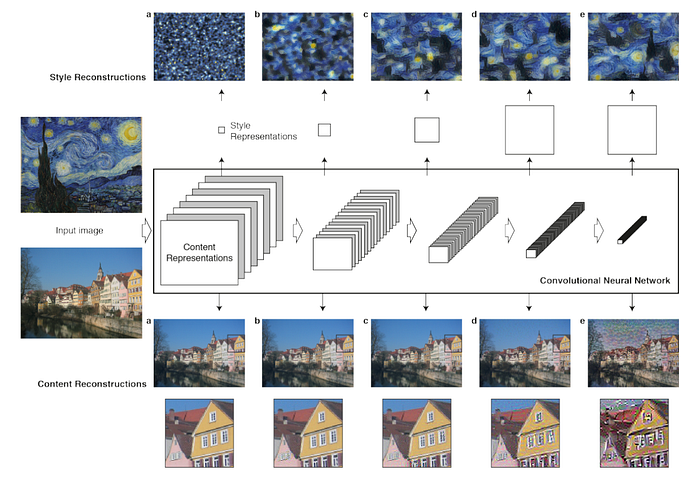
Fast Style Transfer
Paper:A Neural Algorithm of Artistic Style & Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Code: lengstrom/fast-style-transfer
 |
 |
 |
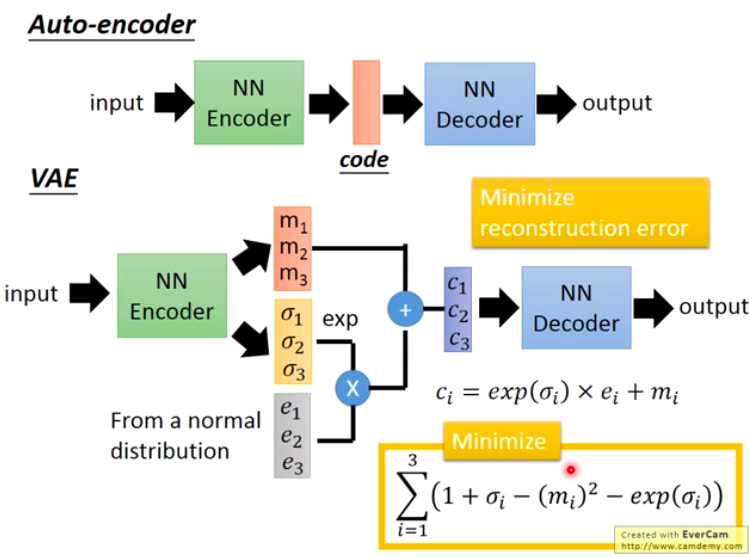
Variational AutoEncoder
VAE
Blog: VAE(Variational AutoEncoder) 實作
Paper: Auto-Encoding Variational Bayes
Code: rkuo2000/fashionmnist-vae


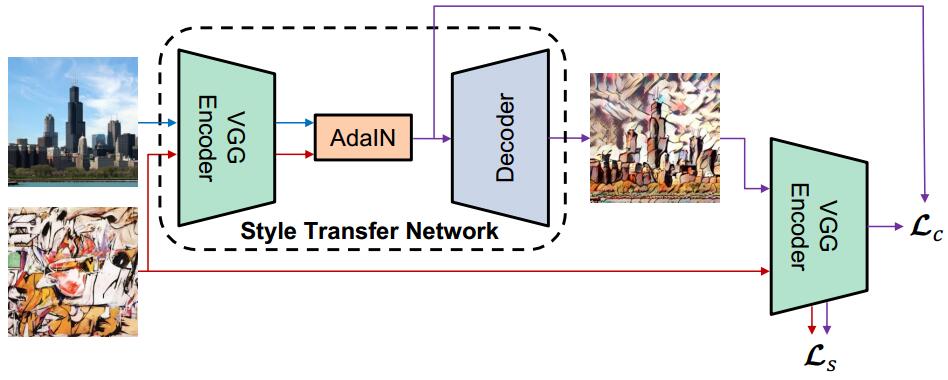
Arbitrary Style Transfer
Paper: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
Code: elleryqueenhomels/arbitrary_style_transfer
 |
 |
 |
 |
 |
 |
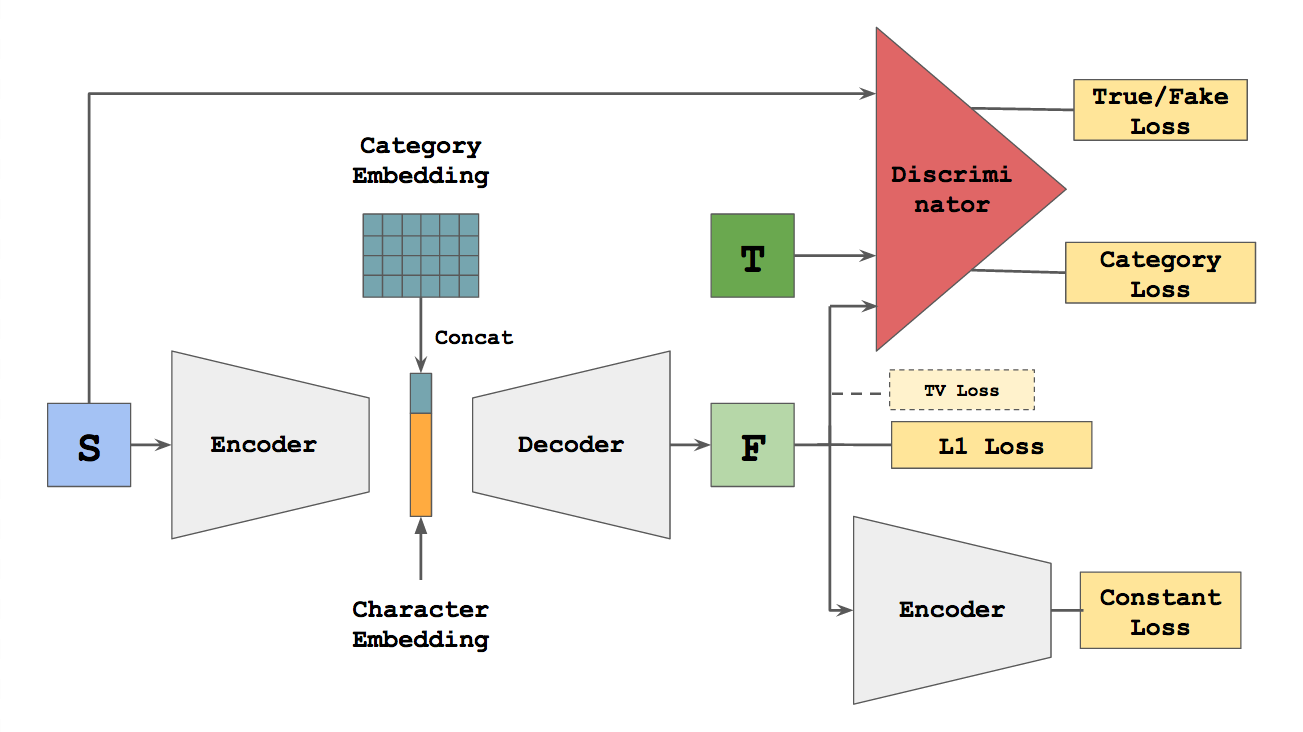
zi2zi
Blog: zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks
Paper: Generating Handwritten Chinese Characters using CycleGAN
Code: kaonashi-tyc/zi2zi

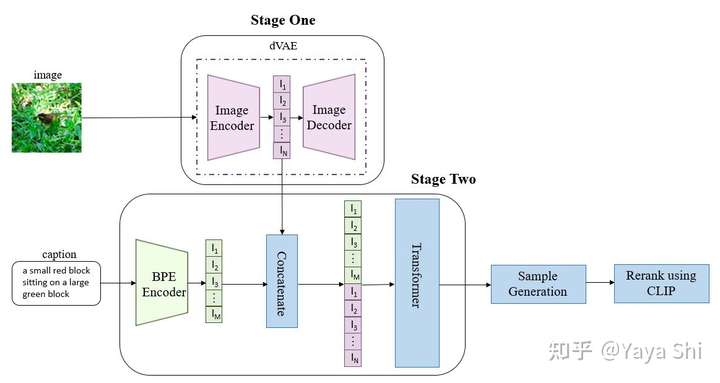
DALL.E
Blog: https://openai.com/blog/dall-e/
DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text–image pairs.
Paper: Zero-Shot Text-to-Image Generation
Code: openai/DALL-E
DALL.E-2
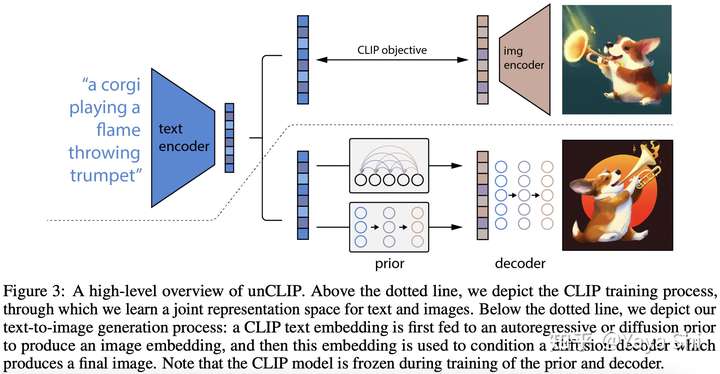
News: An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.
 DALL·E 2 is a new AI system that can create realistic images and art from a description in natural language.
DALL·E 2 is a new AI system that can create realistic images and art from a description in natural language.
Blog: How DALL-E 2 Actually Works
“a bowl of soup that is a portal to another dimension as digital art”.
 Paper: Hierarchical Text-Conditional Image Generation with CLIP Latents
Paper: Hierarchical Text-Conditional Image Generation with CLIP Latents
Stable Diffusion
-
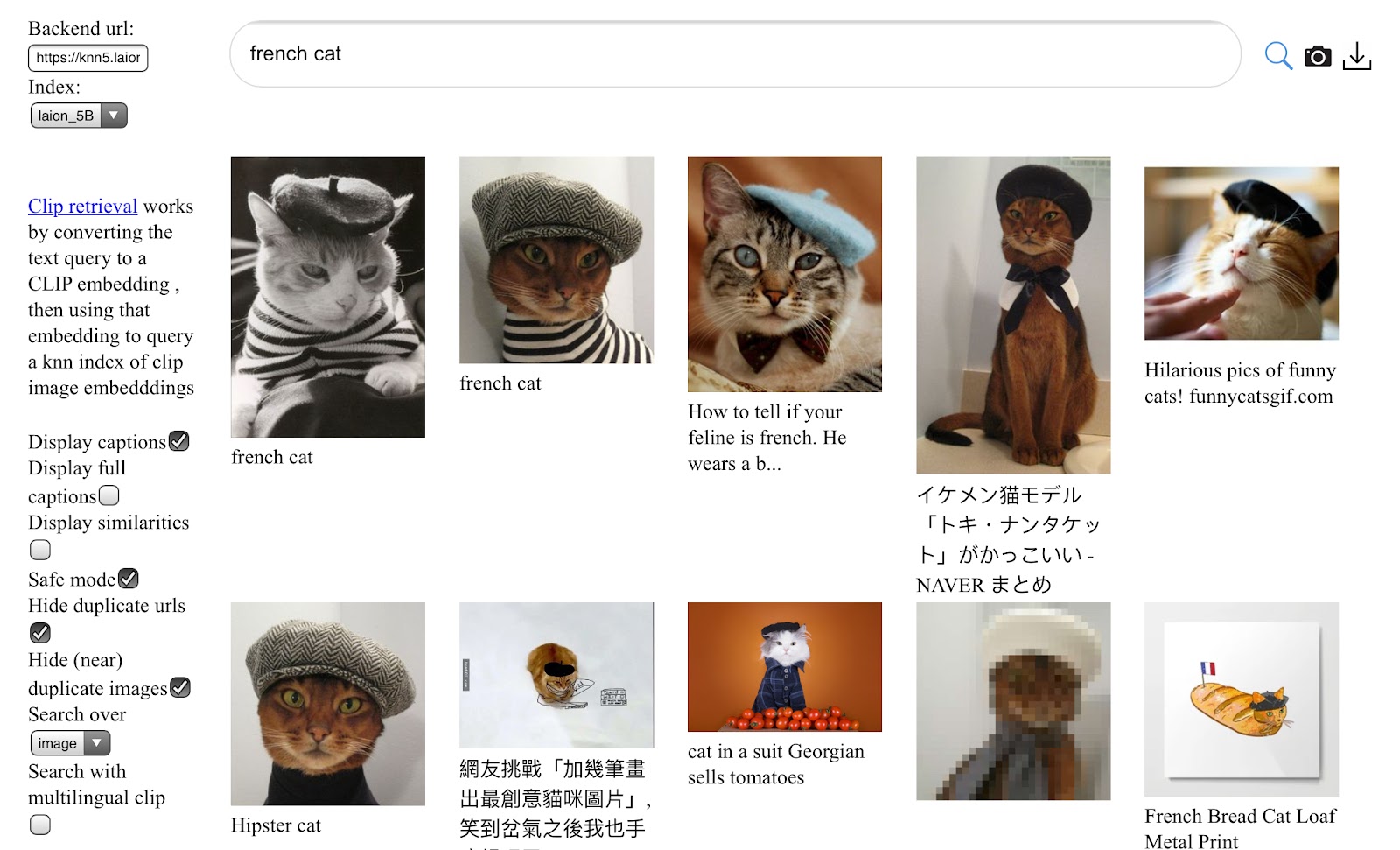
Dataset: LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS
5,85 billion CLIP-filtered image-text pairs
-
Stable Diffusion is a latent text-to-image diffusion model.
 Demo: Stable Diffusion Image Generator
Demo: Stable Diffusion Image Generator -
Image Modification with Stable Diffusion
- Input:

- Output:


- Input:
Paper: High-Resolution Image Synthesis with Latent Diffusion Models
Code: https://github.com/CompVis/latent-diffusion


Paper: Semi-Parametric Neural Image Synthesis

GAN
Blog: A Beginner’s Guide to Generative Adversarial Networks (GANs)
Paper: Generative Adversarial Networks
G是生成的神經網路,它接收一個隨機的噪訊z,通過這個噪訊生成圖片,為G(z)
D是辨别的神經網路,辨别一張圖片夠不夠真實。它的輸入參數是x,x代表一張圖片,輸出D(x)代表x為真實圖片的機率

class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
DCGAN - Deep Convolutional Generative Adversarial Network
Paper: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Code: carpedm20/DCGAN-tensorflow

Generator
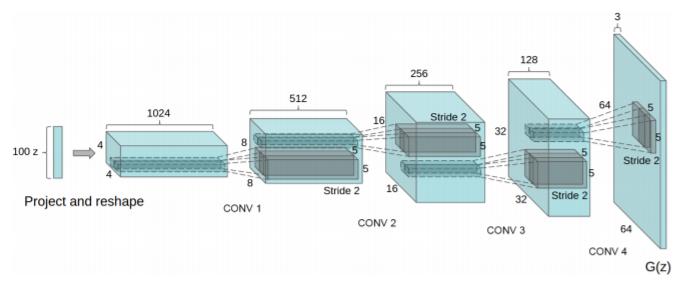
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
DCGAN_LSGAN_WGAN_WGAN-GP_SNGAN_RSGAN_BEGAN_ACGAN_PGGAN_pix2pix_BigGAN
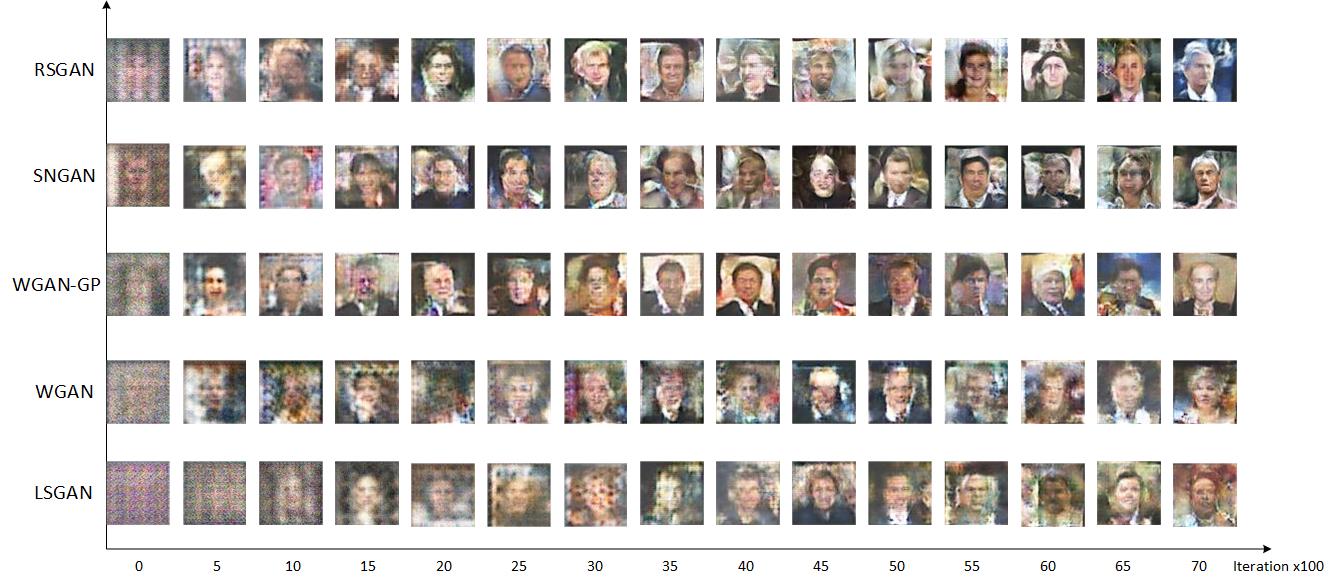
MrCGAN
Paper: Compatibility Family Learning for Item Recommendation and Generation
Code: appier/compatibility-family-learning

pix2pix
Paper: Image-to-Image Translation with Conditional Adversarial Networks
Code: junyanz/pytorch-CycleGAN-and-pix2pix

CycleGAN
Paper: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Code: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix

Tutorial: CycleGAN

# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y,cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
pix2pixHD
Paper: High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Code: NVIDIA/pix2pixHD

vid2vid
Paper: Video-to-Video Synthesis
Code: NVIDIA/vid2vid



Recycle-GAN
Paper: Recycle-GAN: Unsupervised Video Retargeting
Code: aayushbansal/Recycle-GAN

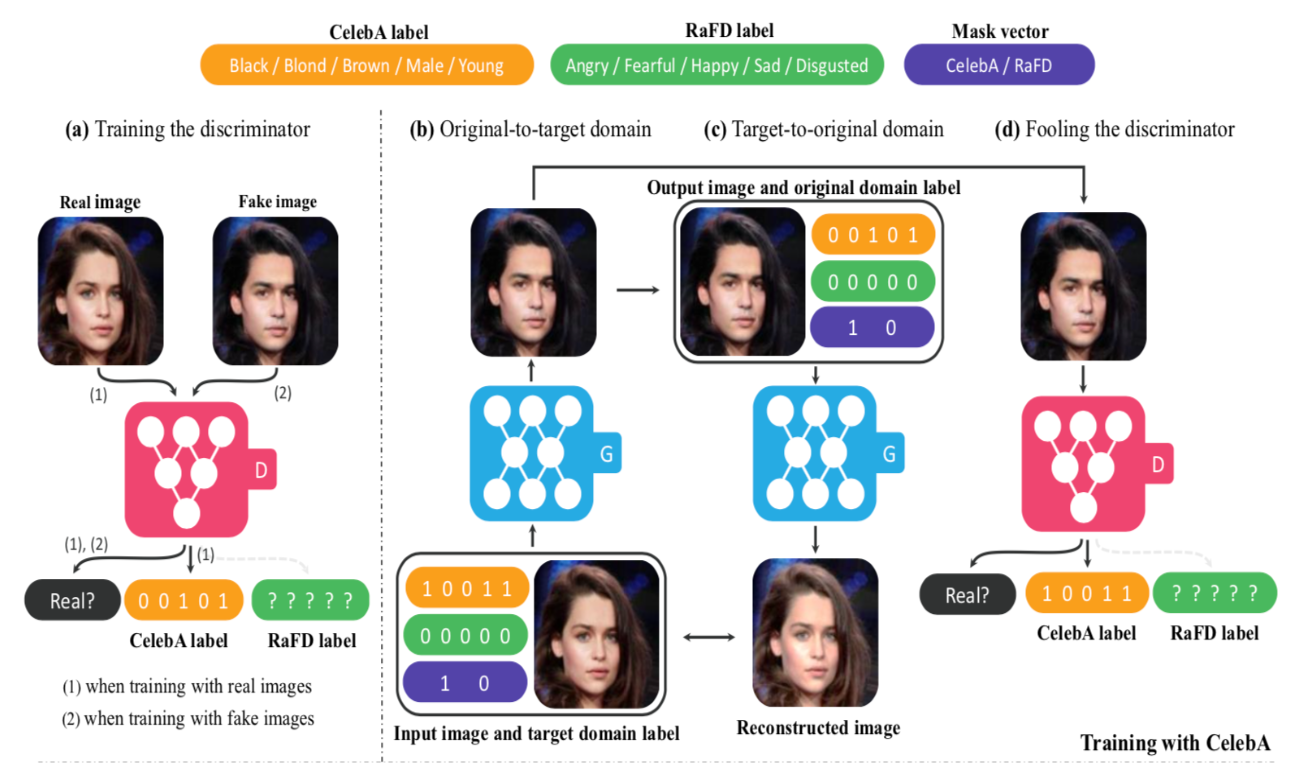
StarGAN
Paper: StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Code: yunjey/stargan



Glow
Blog: https://openai.com/blog/glow/
Paper: Glow: Generative Flow with Invertible 1x1 Convolutions
Code: openai/glow

StyleGAN
Paper: A Style-Based Generator Architecture for Generative Adversarial Networks
Code: NVlabs/stylegan
StyleGAN 2
Blog: Understanding the StyleGAN and StyleGAN2 Architecture
Paper: A Style-Based Generator Architecture for Generative Adversarial Networks
Code: hNVlabs/stylegan2-ada-pytorch
StyleGAN2-ADA
Paper: Training Generative Adversarial Networks with Limited Data
Code: hNVlabs/stylegan2-ada-pytorch

StyleGAN2 Distillation
Paper: StyleGAN2 Distillation for Feed-forward Image Manipulation
Code: EvgenyKashin/stylegan2-distillation



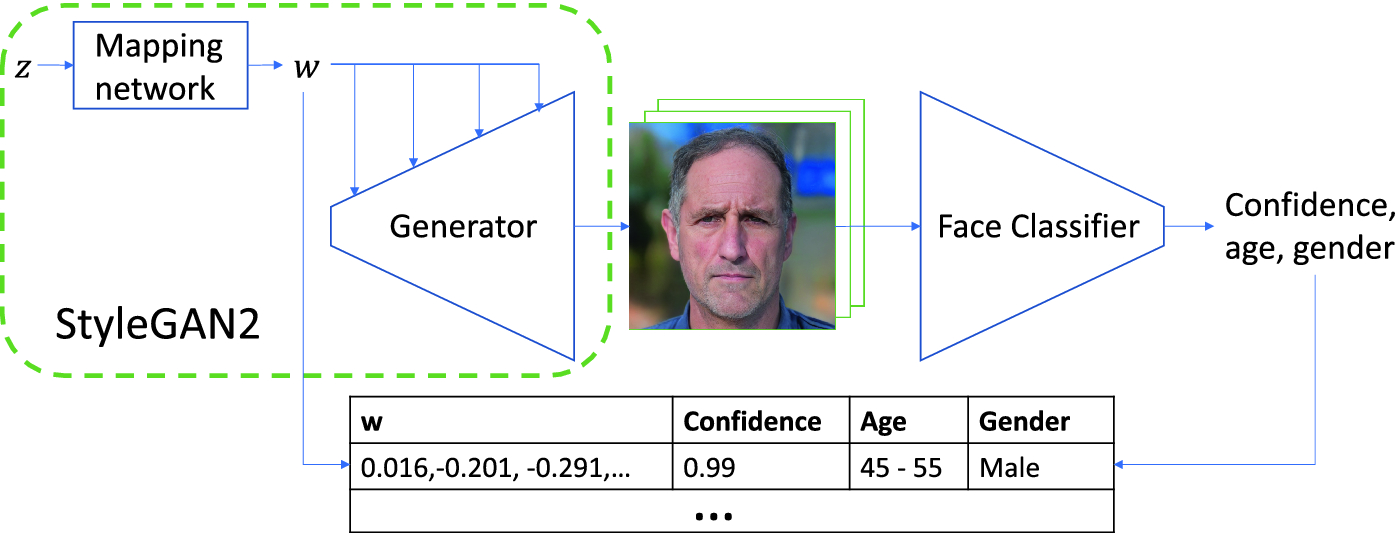
Toonify
Blog: StyleGAN network blending

Paper: Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains
Code: justinpinkney/toonify

Face Sketch Synthesis
Paper: Face Sketch Synthesis via Semantic-Driven Generative Adversarial Network


pix2style2pix
Code: eladrich/pixel2style2pixel

Face Datasets
Celeb-A HQ Dataset

Flickr-Faces-HQ Dataset (FFHQ)

MetFaces dataset

Animal Faces-HQ dataset (AFHQ)
Animal Faces-HQ (AFHQ), consisting of 15,000 high-quality images at 512×512 resolution
The dataset includes three domains of cat, dog, and wildlife, each providing about 5000 images.

Ukiyo-e Faces

Cartoon Faces

GANimation
Blog: GANimation: Anatomically-aware Facial Animation from a Single Image
Paper: GANimation: Anatomically-aware Facial Animation from a Single Image
Code: albertpumarola/GANimation
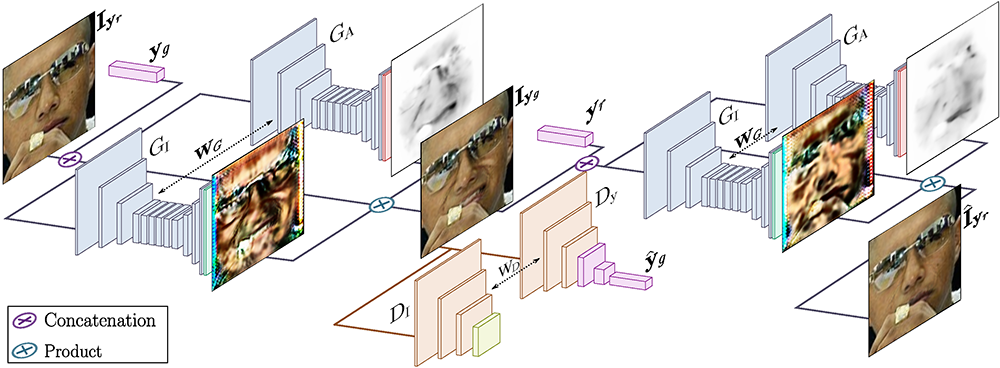
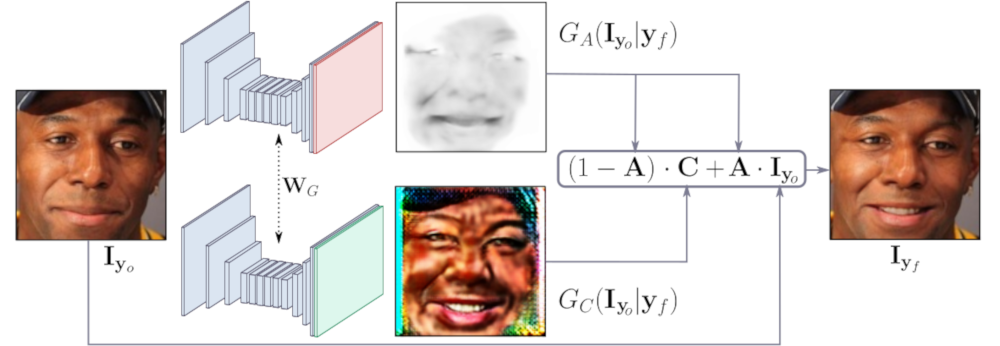

Sefa
Blog: https://genforce.github.io/sefa/
Paper: Closed-Form Factorization of Latent Semantics in GANs
Code: genforce/sefa
| Pose | Mouth | Eye |
 |
 |
 |
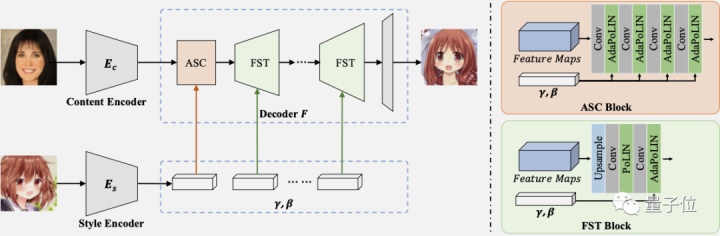
AniGAN
Blog: 博士後小姐姐把「二次元老婆生成器」升級了:這一次可以指定畫風
Paper: AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation


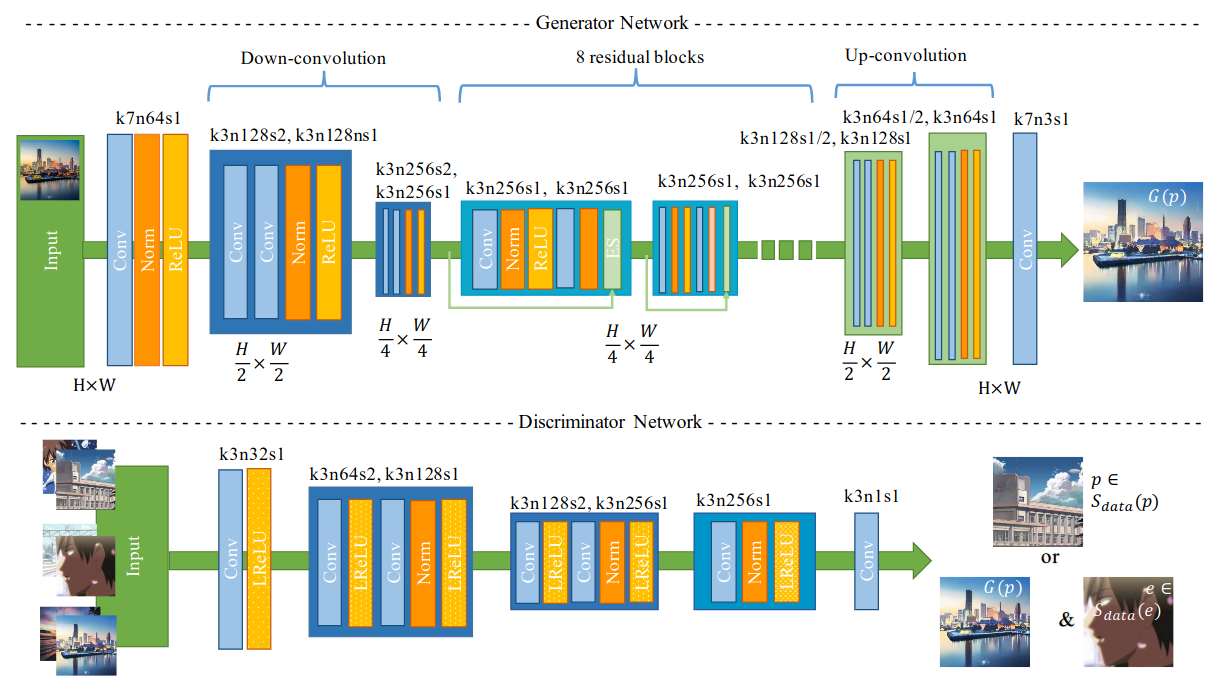
CartoonGAN
Blog: Generate Anime using CartoonGAN and Tensorflow 2.0
Paper: CartoonGAN
Code: mnicnc404/CartoonGan-tensorflow

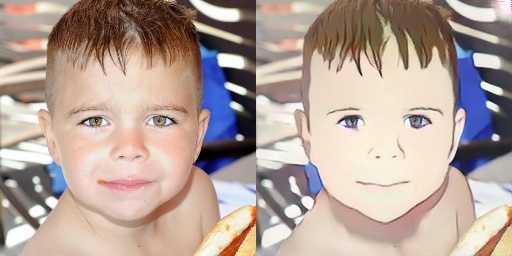
Cartoon-GAN
Paper: Generative Adversarial Networks for photo to Hayao Miyazaki style cartoons
Code: FilipAndersson245/cartoon-gan


White-box Cartoonization
Paper: White-Box Cartoonization Using An Extended GAN Framework
Code: SystemErrorWang/White-box-Cartoonization


Code: White-box facial image cartoonizaiton
GAN Compression
Paper: GAN Compression: Efficient Architectures for Interactive Conditional GANs
Code: mit-han-lab/gan-compression


SRGAN
Paper: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Code: tensorlayer/srgan


SingleHDR
Paper: Single-Image HDR Reconstruction by Learning to Reverse the Camera Pipeline
Code: alex04072000/SingleHDR

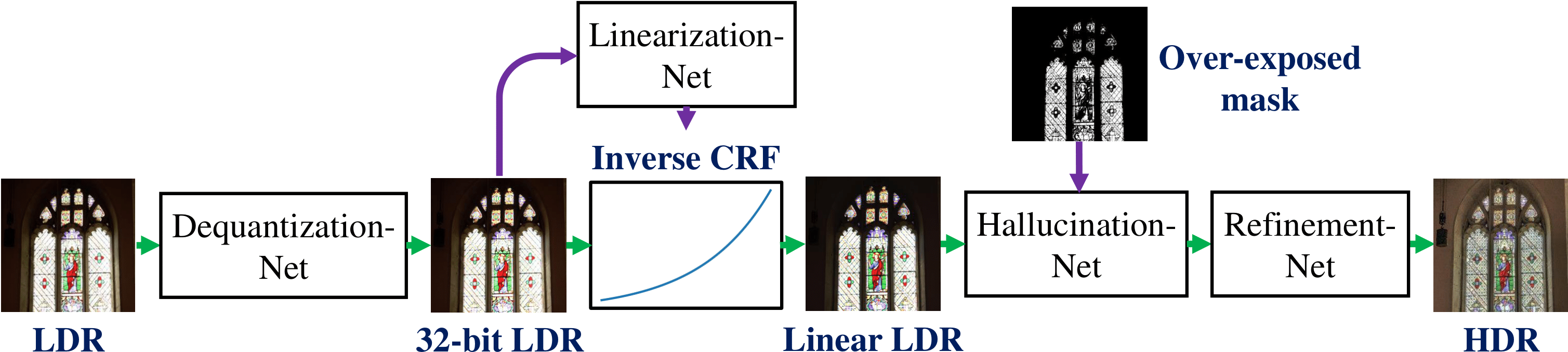
Image Inpainting
High-Resolution Image Inpainting
Blog: Review: High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis
Paper: High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis
Code: leehomyc/Faster-High-Res-Neural-Inpainting

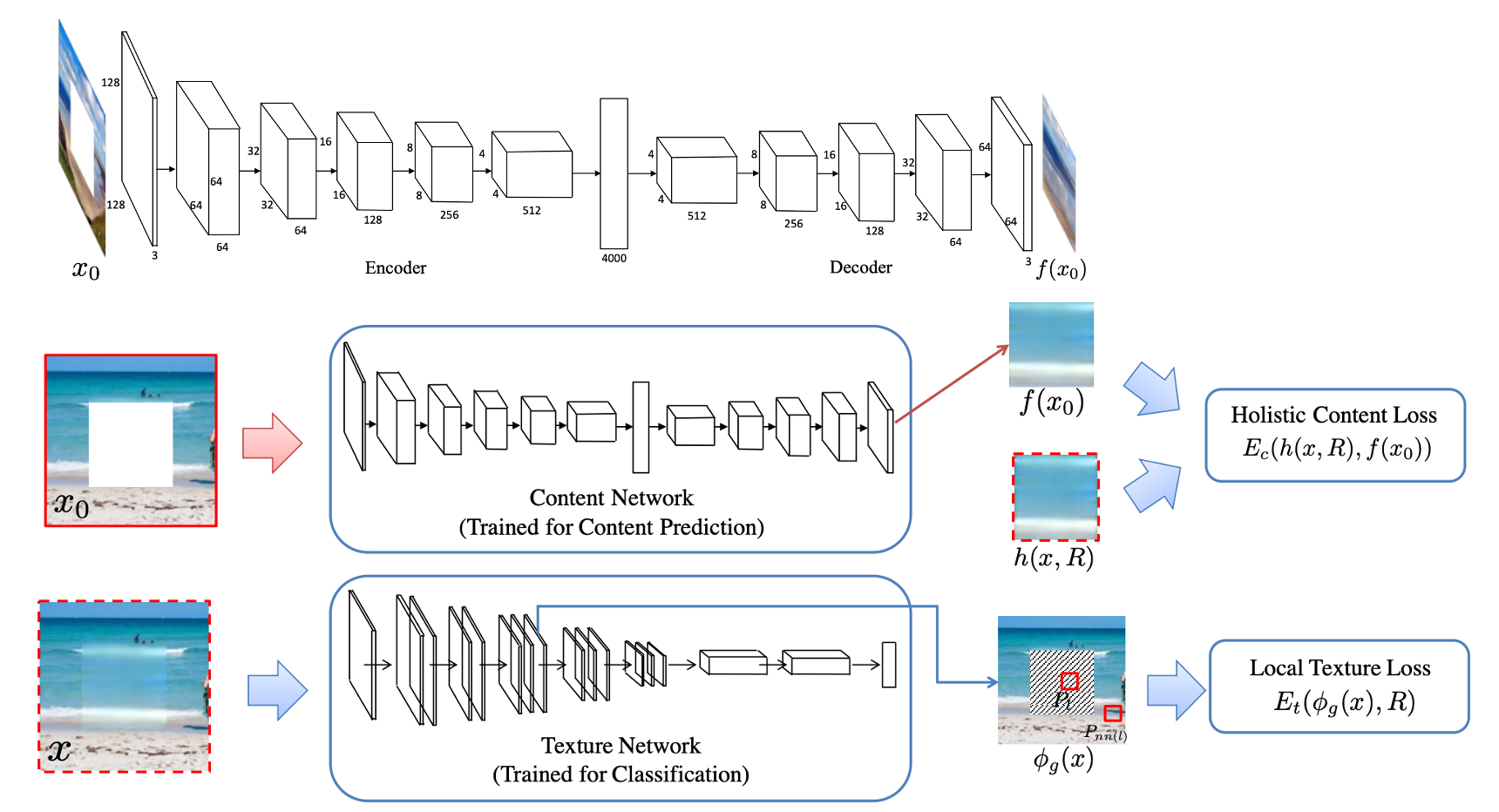
Image Inpainting for Irregular Holes
Blog: Image Inpainting for Irregular Holes Using Partial Convolutions
Paper: Image Inpainting for Irregular Holes Using Partial Convolutions
Code: NVIDIA/partialconv

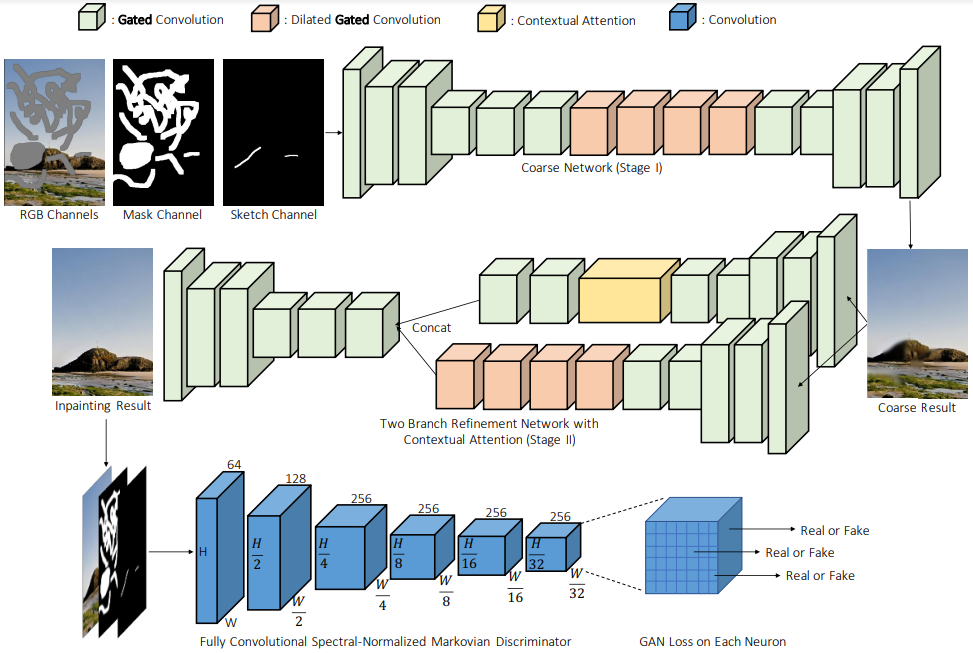
DeepFill V2
Blog: A Practical Generative Deep Image Inpainting Approach
Paper: Free-Form Image Inpainting with Gated Convolution
Code: JiahuiYu/generative_inpainting
 |
 |
 |

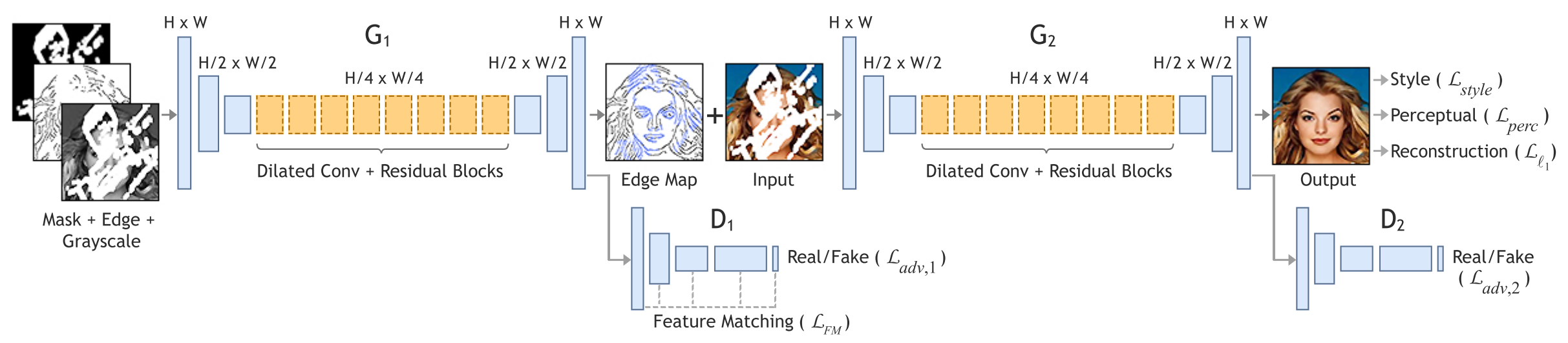
EdgeConnect
Paper: EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
Code: knazeri/edge-connect

Deep Flow-Guided Video Inpainting
Paper: Deep Flow-Guided Video Inpainting
Code: nbei/Deep-Flow-Guided-Video-Inpainting


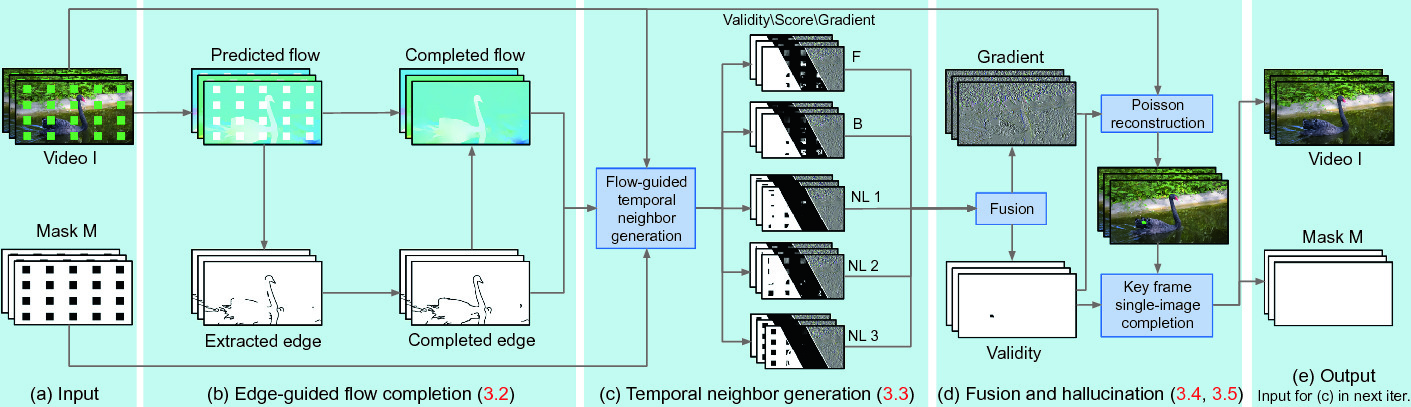
Flow-edge Guided Video Completion
Paper: Flow-edge Guided Video Completion
Code: vt-vl-lab/FGVC
GauGAN
Paper: Semantic Image Synthesis with Spatially-Adaptive Normalization
Code: NVlabs/SPADE
 |
 |
DeepFaceDrawing
Paper: Deep Generation of Face Images from Sketches
Code: franknb/Drawing-to-Face

Pose-guided Person Image Generation
Paper: Pose Guided Person Image Generation
Code: charliememory/Pose-Guided-Person-Image-Generation

PoseGAN
Paper: Deformable GANs for Pose-based Human Image Generation
Code: AliaksandrSiarohin/pose-gan


Everybody Dance Now
Blog: https://carolineec.github.io/everybody_dance_now/
Paper: Everybody Dance Now
Code: carolineec/EverybodyDanceNow
Virtual Try On (VTON)
VITON
Paper: VITON: An Image-based Virtual Try-on Network

MG-VTON
Paper: Towards Multi-pose Guided Virtual Try-on Network


Poly-GAN
Paper: Poly-GAN: Multi-Conditioned GAN for Fashion Synthesis
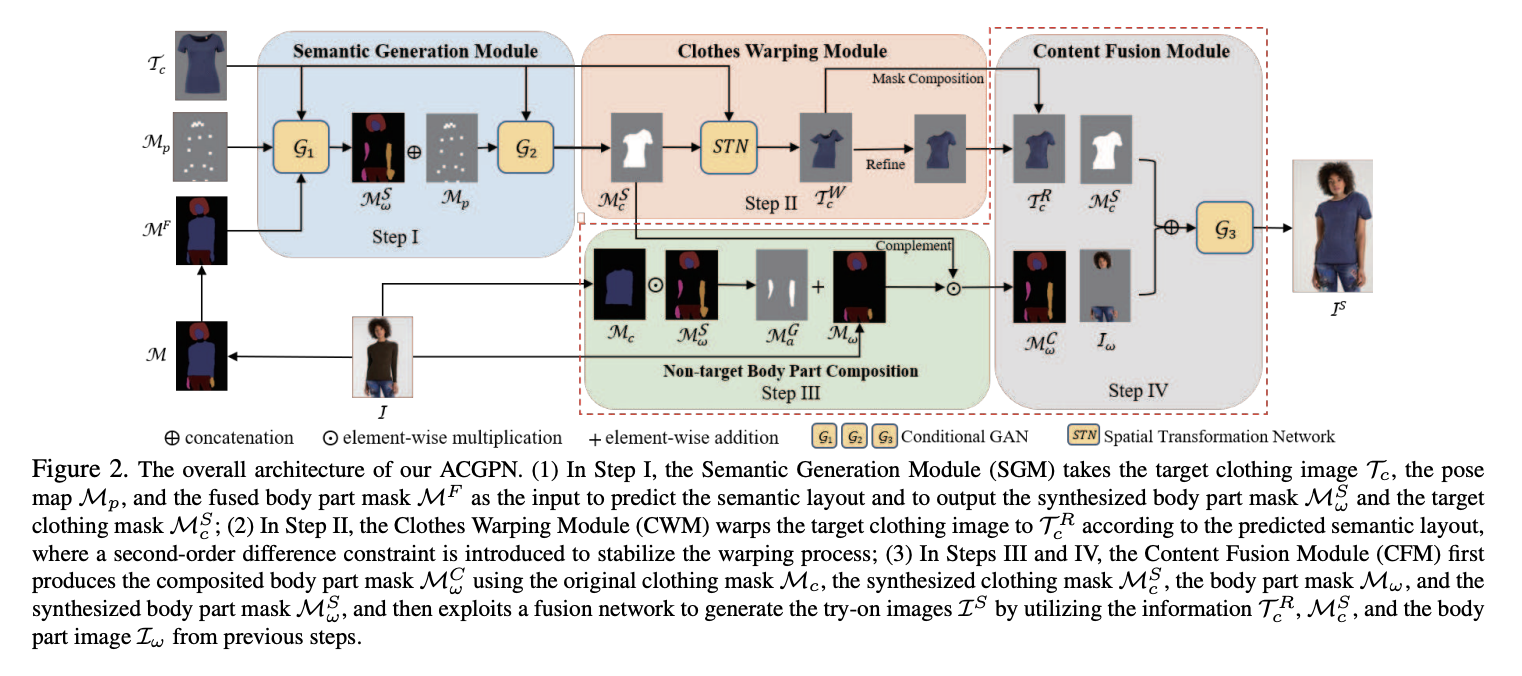
ACGPN
Paper: Towards Photo-Realistic Virtual Try-On by Adaptively Generating↔Preserving Image Content
Code: switchablenorms/DeepFashion_Try_On
SMIS
Blog: https://seanseattle.github.io/SMIS/
Paper: Semantically Multi-modal Image Synthesis
Code: Seanseattle/SMIS


CP-VTON+
Paper: CP-VTON+: Clothing Shape and Texture Preserving Image-Based Virtual Try-On
Code: minar09/cp-vton-plus


O-VITON
Paper: Image Based Virtual Try-on Network from Unpaired Data
Code: trinanjan12/Image-Based-Virtual-Try-on-Network-from-Unpaired-Data
Inference Flow
Training Flow
PF-AFN
Paper: Parser-Free Virtual Try-on via Distilling Appearance Flows
Code: geyuying/PF-AFN


CIT
Paper: Cloth Interactive Transformer for Virtual Try-On
Code: Amazingren/CIT




![]()
pix2surf
Paper: Learning to Transfer Texture from Clothing Images to 3D Humans
Code: polobymulberry/pix2surf

TailorNet
Paper: TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style
Code: chaitanya100100/TailorNet
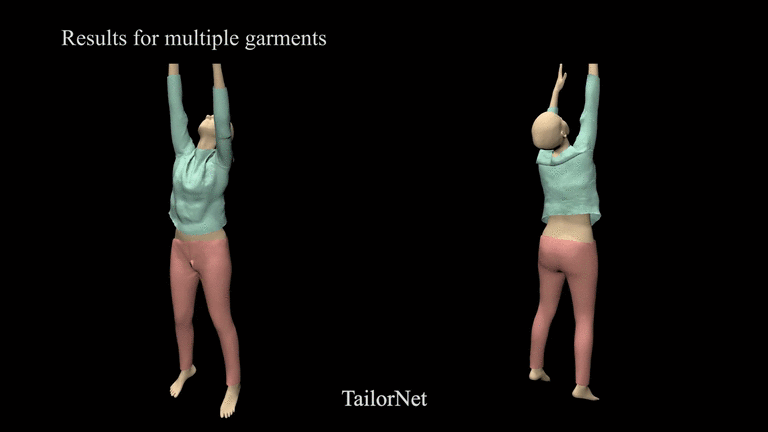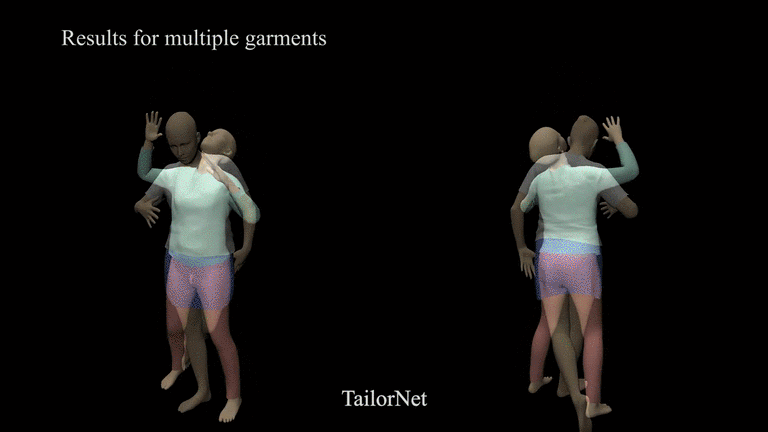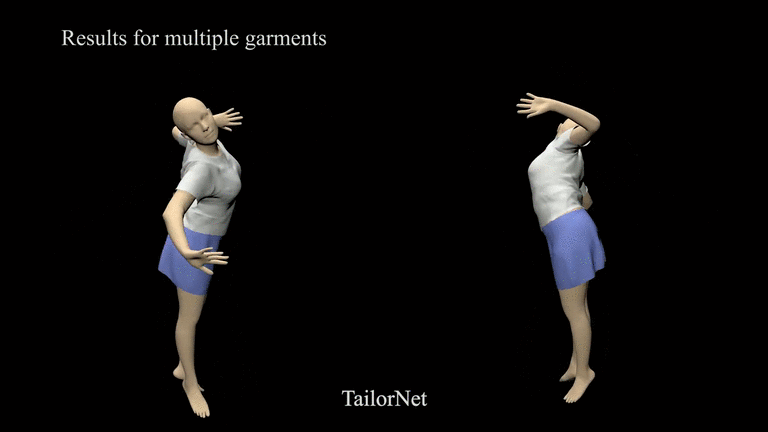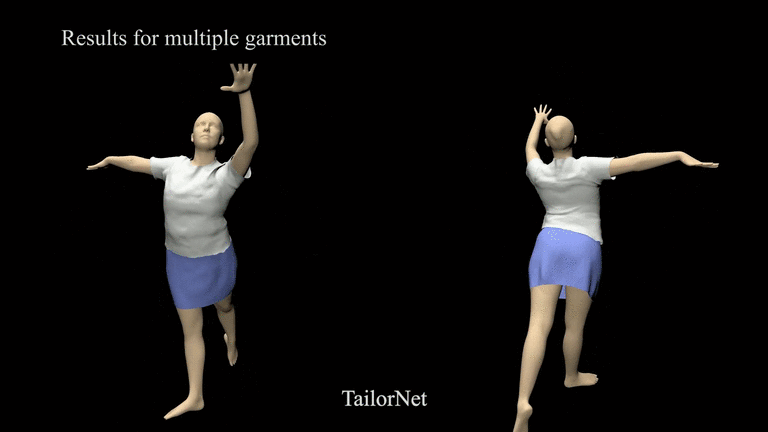
3D Avatar
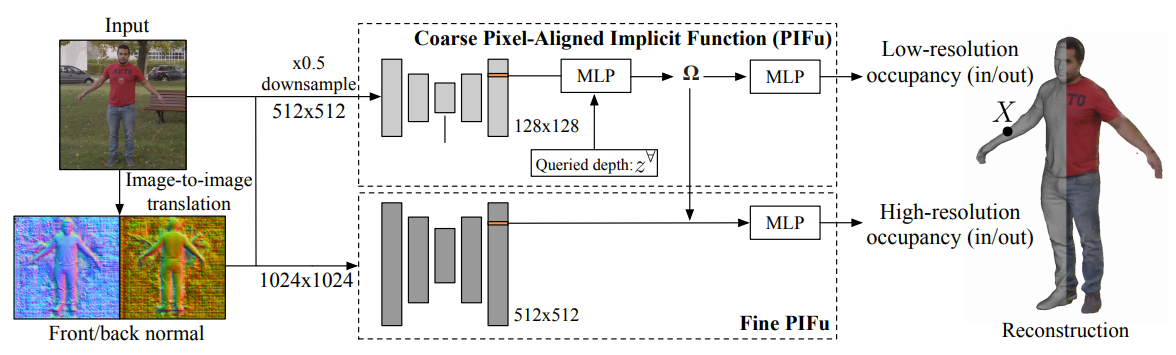
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Blog: PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Paper: PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Code: facebookresearch/pifuhd

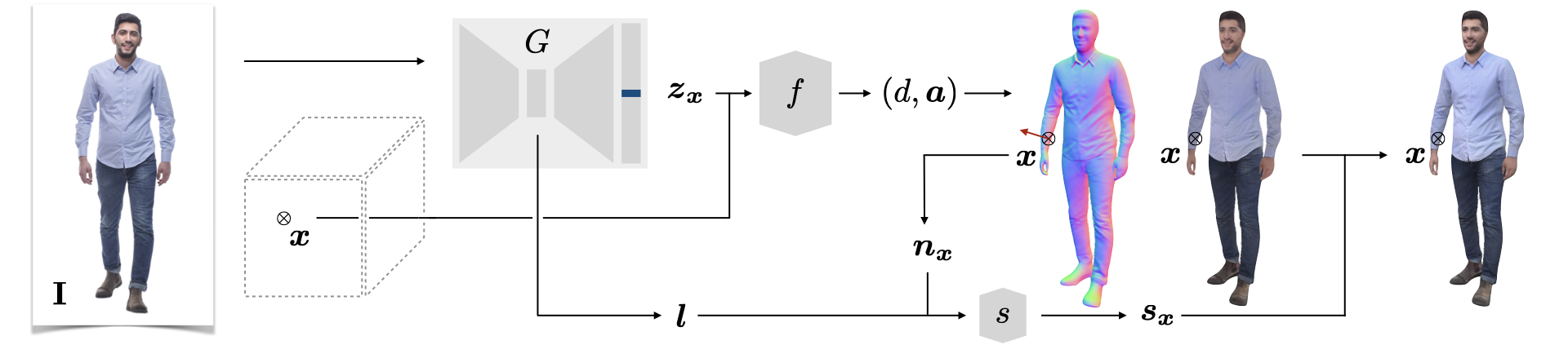
gDNA: Towards Generative Detailed Neural Avatars
Blog: PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Paper: gDNA: Towards Generative Detailed Neural Avatars
 To generate diverse 3D humans, we build an implicit multi-subject articulated model. We model clothed human shapes and detailed surface normals in a pose-independent canonical space via a neural implicit surface representation, conditioned on latent codes.
To generate diverse 3D humans, we build an implicit multi-subject articulated model. We model clothed human shapes and detailed surface normals in a pose-independent canonical space via a neural implicit surface representation, conditioned on latent codes.
Phorhum
Paper: Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing
NeRF
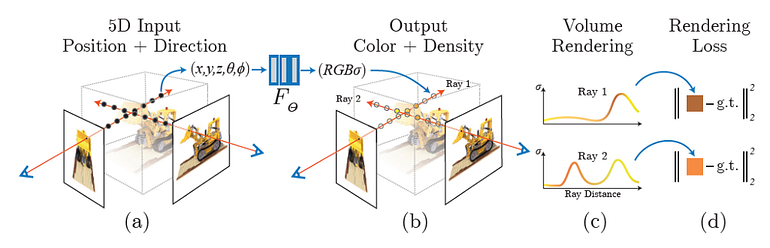
NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis
Paper: arxiv.org/abs/2003.08934
Code: bmild/nerf
Colab: tiny_nerf
Kaggle: rkuo2000/tiny-nerf

 The algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location (x, y, z) and viewing direction (θ, φ)) and whose output is the volume density and view-dependent emitted radiance at that spatial location.
The algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location (x, y, z) and viewing direction (θ, φ)) and whose output is the volume density and view-dependent emitted radiance at that spatial location.
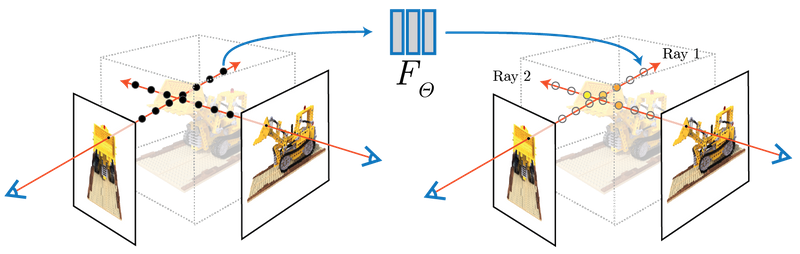 We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis.
We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis.
FastNeRF
Paper: FastNeRF: High-Fidelity Neural Rendering at 200FPS
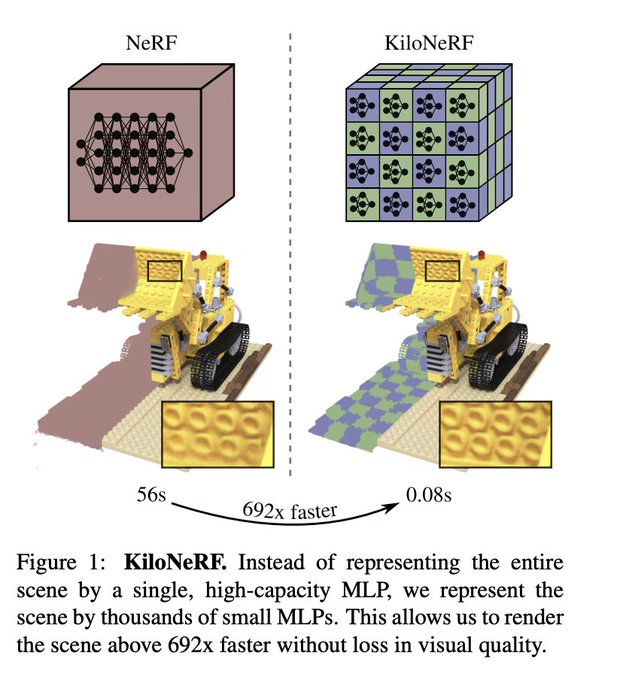
KiloNeRF
Paper: KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
Code: creiser/kilonerf

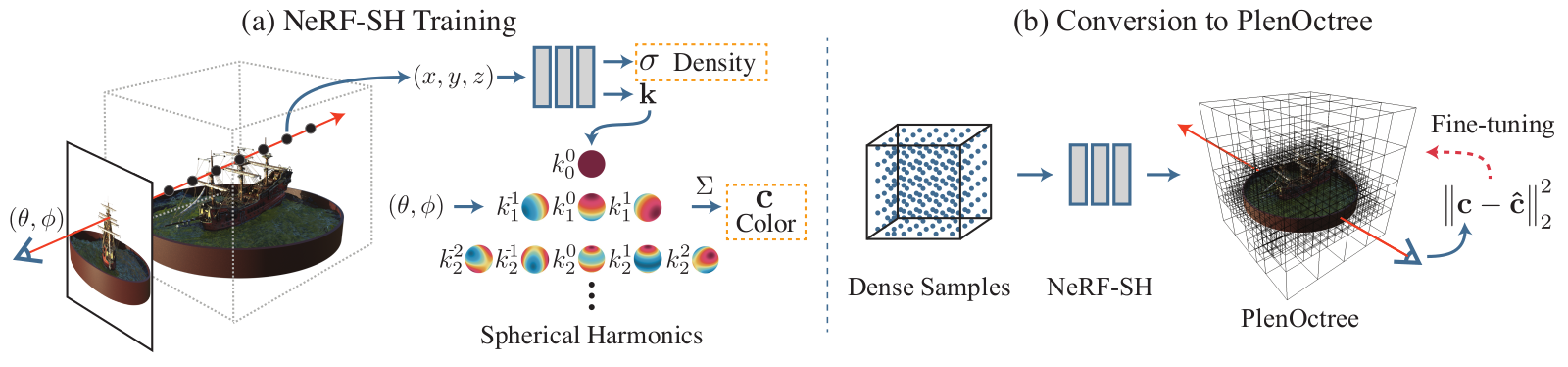
PlenOctrees
Paper: PlenOctrees for Real-time Rendering of Neural Radiance Fields
Code: NeRF-SH training and conversion & Volume Rendering
Sparse Neural Radiance Grids (SNeRG)
Paper: Baking Neural Radiance Fields for Real-Time View Synthesis
Code: google-research/snerg
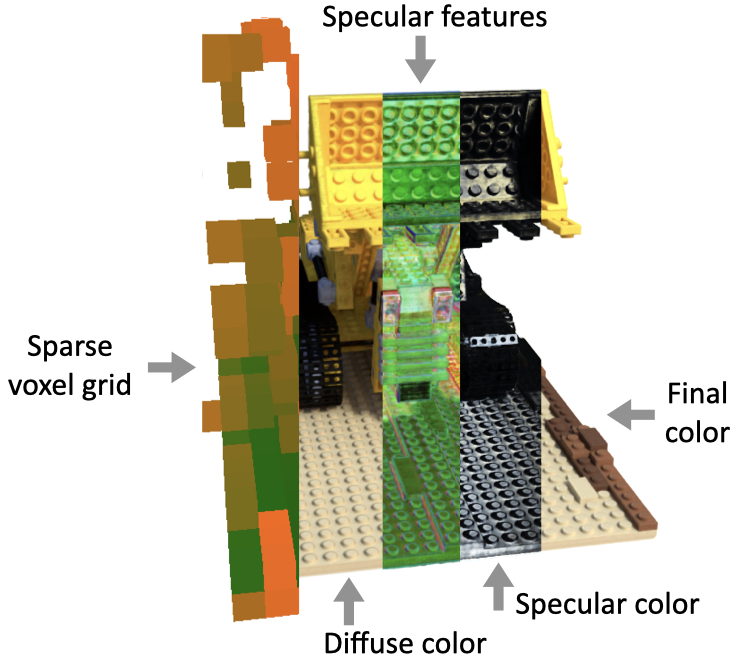
Faster Neural Radiance Fields Inference
- NeRF Inference: Probabilistic Approach
- Faster Inference: Efficient Ray-Tracing + Image Decomposition
| Method Render | time | Speedup |
| NeRF | 56185 ms | – |
| NeRF + ESS + ERT | 788 ms | 71 |
| KiloNeRF | 22 ms | 2548 |
- Sparse Voxel Grid and Octrees: Spatial Sparsity
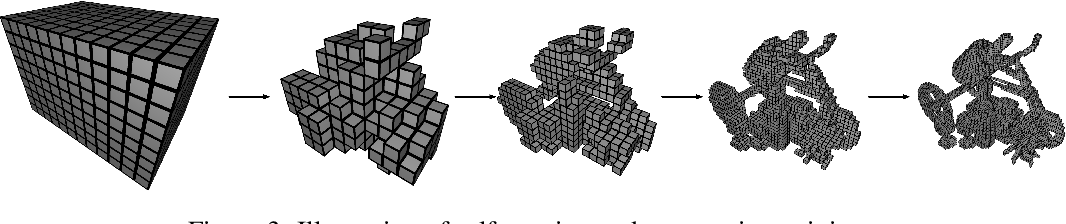
- Neural Sparse Voxel Fields proposed learn a sparse voxel grid in a progressive manner that increases the resolution of the voxel grid at a time to not just such represent explicit geomety but also to learn the implicit features per non-empty voxel.
- PlenOctree also uses the octree structure to speed up the geometry queries and store the view-dependent color representation on the leaves.
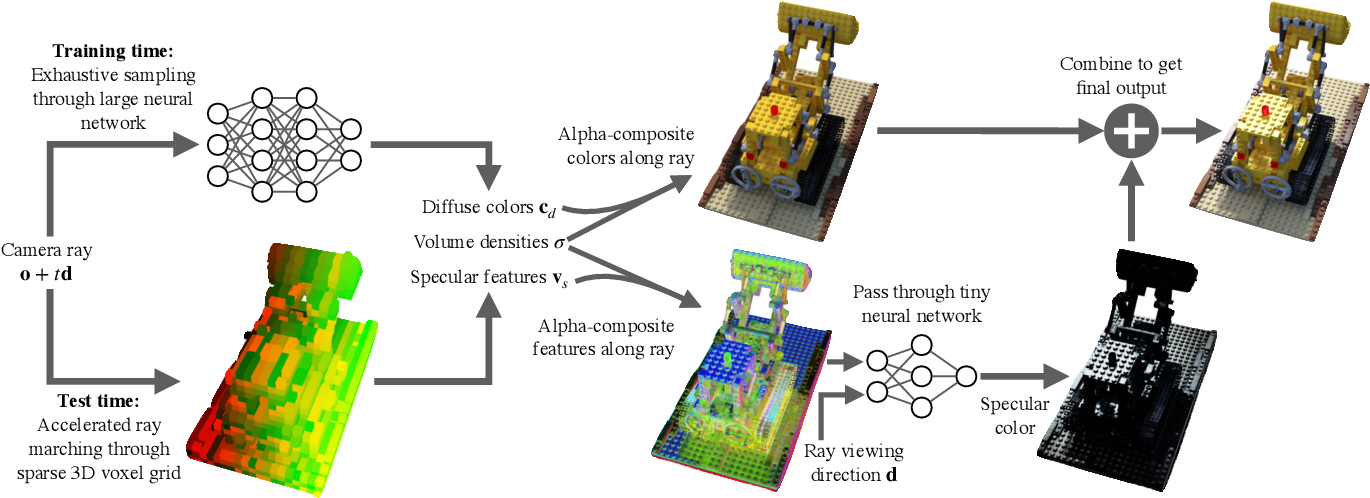
- KiloNeRF proposes to decompose this large deep NeRF into a set of small shallow NeRFs that capture only a small portion of the space.
- Baking Neural Radiance Fields (SNeRG) proposes to decompose an image into the diffuse color and specularity so that the inference network handles a very simple task.
Point-NeRF
Paper: Point-NeRF: Point-based Neural Radiance Fields
Code: Xharlie/pointnerf
 Point-NeRF uses neural 3D point clouds, with associated neural features, to model a radiance field.
Point-NeRF uses neural 3D point clouds, with associated neural features, to model a radiance field.
SqueezeNeRF
Paper: SqueezeNeRF: Further factorized FastNeRF for memory-efficient inference

Nerfies: Deformable Neural Radiance Fields
Paper: Nerfies: Deformable Neural Radiance Fields
Code: google/nerfies
Light Field Networks
Paper: Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Code: Light Field Networks
Face Swap
faceswap-GAN
Code: https://github.com/shaoanlu/faceswap-GAN
DeepFake
Paper: DeepFaceLab: Integrated, flexible and extensible face-swapping framework
Github: iperov/DeepFaceLab
DeepFake Detection Challenge
ObamaNet
Paper: ObamaNet: Photo-realistic lip-sync from text
Code: acvictor/Obama-Lip-Sync

Talking Face
Paper: Talking Face Generation by Adversarially Disentangled Audio-Visual Representation
Code: Hangz-nju-cuhk/Talking-Face-Generation-DAVS

Neural Talking Head
Blog: Creating Personalized Photo-Realistic Talking Head Models
Paper: Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Code: vincent-thevenin/Realistic-Neural-Talking-Head-Models


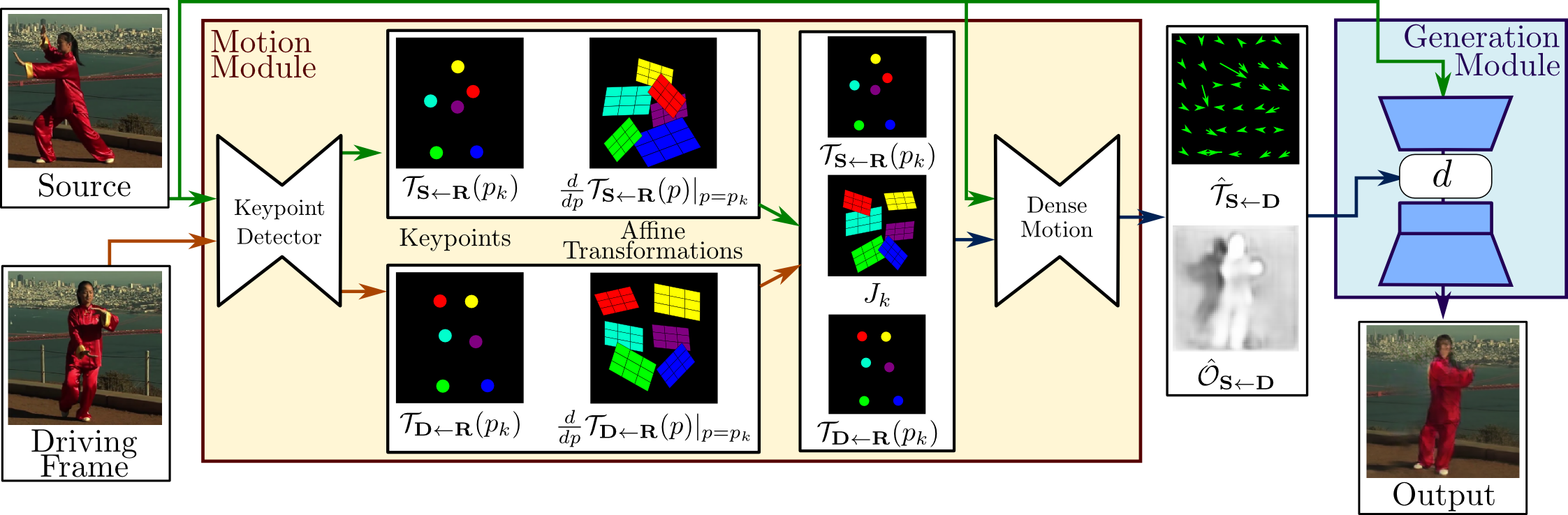
First Order Model
Blog: First Order Motion Model for Image Animation
Paper: First Order Motion Model for Image Animation
Code: AliaksandrSiarohin/first-order-model


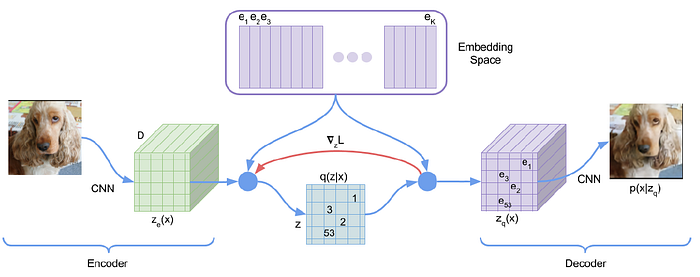
VQ-AVE
Blog: 帶你認識Vector-Quantized Variational AutoEncoder - 理論篇
Paper: Neural Discrete Representation Learning
Paper: Generating Diverse High-Fidelity Images with VQ-VAE-2

Music Seperation
Spleeter
Paper: Spleeter: A FAST AND STATE-OF-THE ART MUSIC SOURCE
SEPARATION TOOL WITH PRE-TRAINED MODELS
Code: deezer/spleeter
Wave-U-Net
Paper: Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
Code: f90/Wave-U-Net

Hyper Wave-U-Net
Paper: Improving singing voice separation with the Wave-U-Net using Minimum Hyperspherical Energy
Code: jperezlapillo/hyper-wave-u-net
MHE regularisation:

Demucs
Paper: Music Source Separation in the Waveform Domain
Code: facebookresearch/demucs
Deep Singer
OpenAI Jukebox
Blog: Jukebox
model modified from VQ-VAE-2
Paper: Jukebox: A Generative Model for Music
Colab: Interacting with Jukebox
DeepSinger
Blog: Microsoft’s AI generates voices that sing in Chinese and English
Paper: DeepSinger: Singing Voice Synthesis with Data Mined From the Web
Demo: DeepSinger: Singing Voice Synthesis with Data Mined From the Web
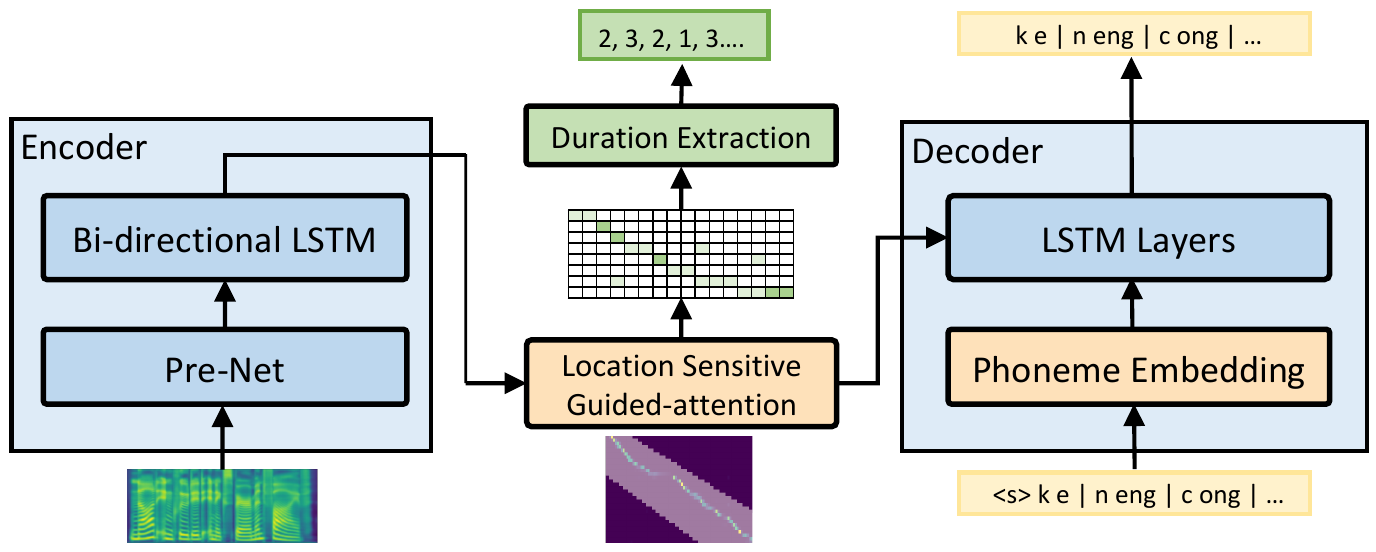
The alignment model based on the architecture of automatic speech recognition
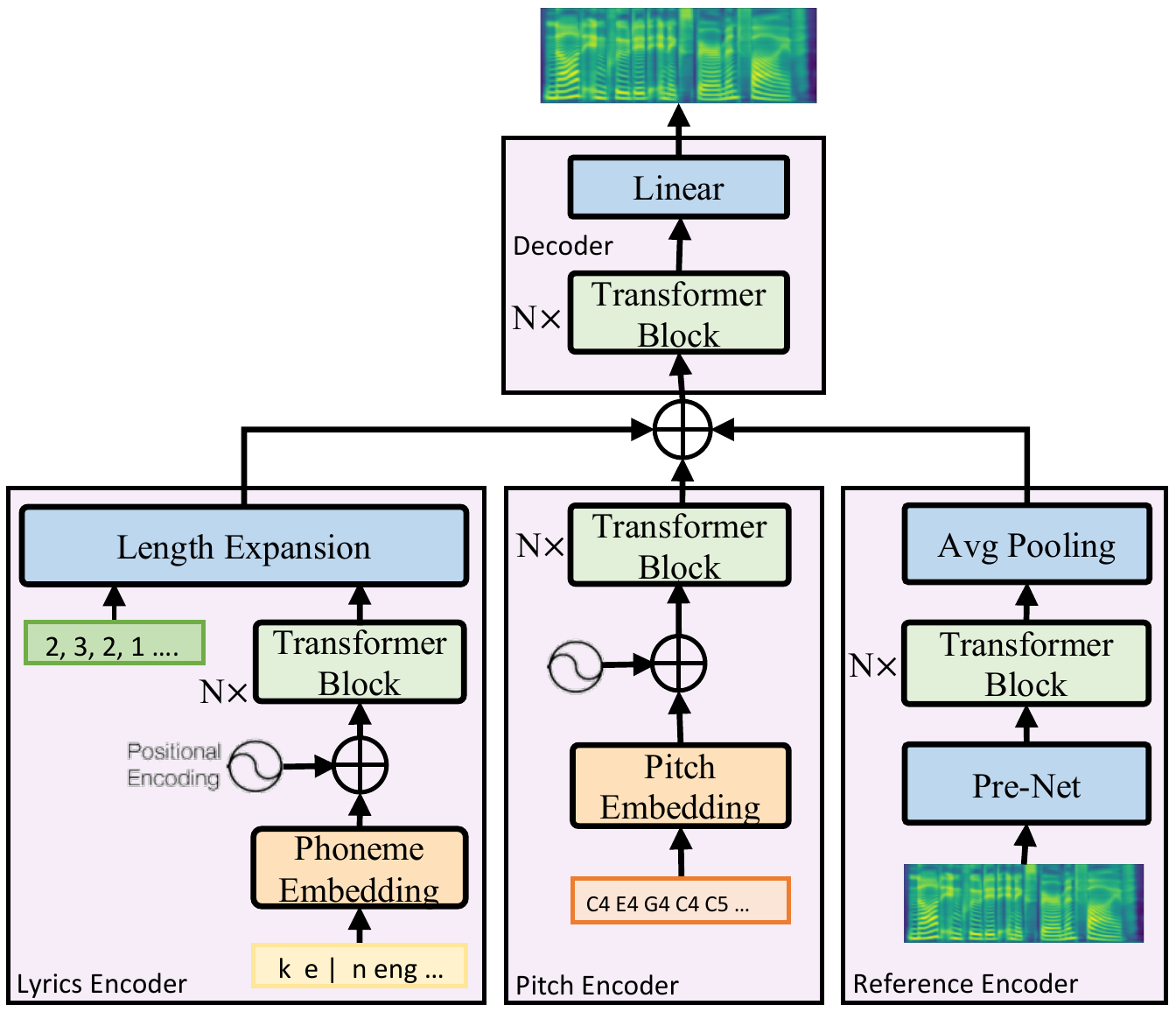
The architecture of the singing model
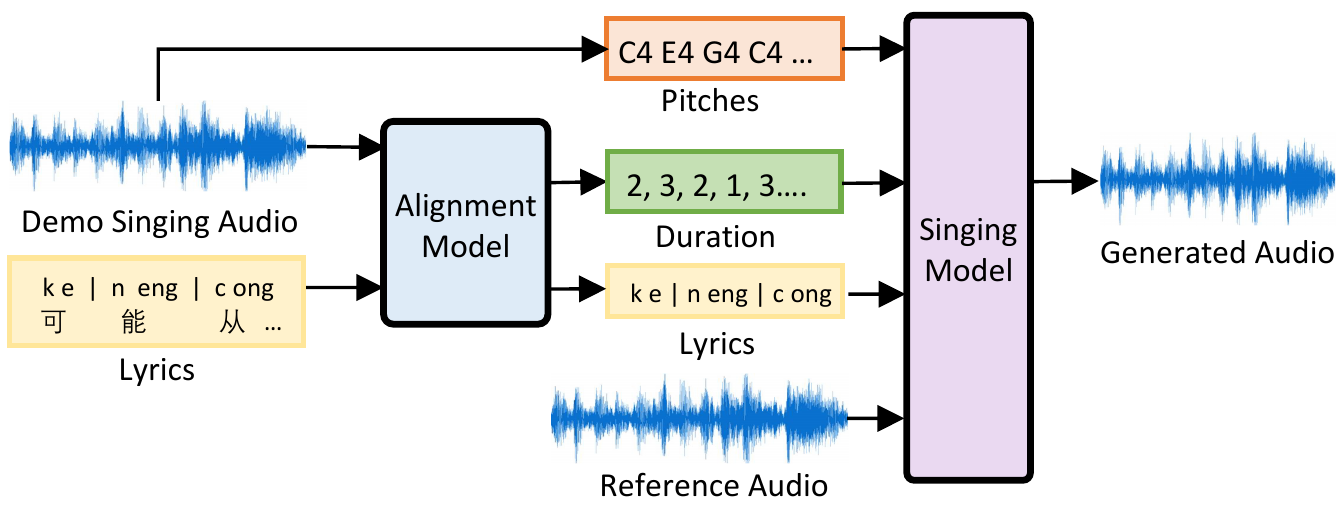
The inference process of singing voice synthesis
Voice Conversion
Paper: An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning

Blog: Voice Cloning Using Deep Learning
Deep Voice 3
Blog: Deep Voice 3: Scaling Text to Speech with Convolutional Sequence Learning
Paper: Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Code: r9y9/deepvoice3_pytorch
Code: Kyubyong/deepvoice3

Neural Voice Cloning
Paper: Neural Voice Cloning with a Few Samples
Code: SforAiDl/Neural-Voice-Cloning-With-Few-Samples

SV2TTS
Blog: Voice Cloning: Corentin’s Improvisation On SV2TTS
Paper: Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Code: CorentinJ/Real-Time-Voice-Cloning
Synthesizer : The synthesizer is Tacotron2 without Wavenet
SV2TTS Toolbox
MelGAN-VC
Paper: MelGAN-VC: Voice Conversion and Audio Style Transfer on arbitrarily long samples using Spectrograms
Code: marcoppasini/MelGAN-VC

Vocoder-free End-to-End Voice Conversion
Paper: Vocoder-free End-to-End Voice Conversion with Transformer Network
Code: kaen2891/kaen2891.github.io

ConVoice
Paper: ConVoice: Real-Time Zero-Shot Voice Style Transfer with Convolutional Network
Demo: ConVoice: Real-Time Zero-Shot Voice Style Transfer

This site was last updated December 22, 2022.