Pose Estimation
Pose Estimation includes Applications, Body Pose, Head Pose, Hand Pose , Object Pose.
Pose Estimation Applications
-
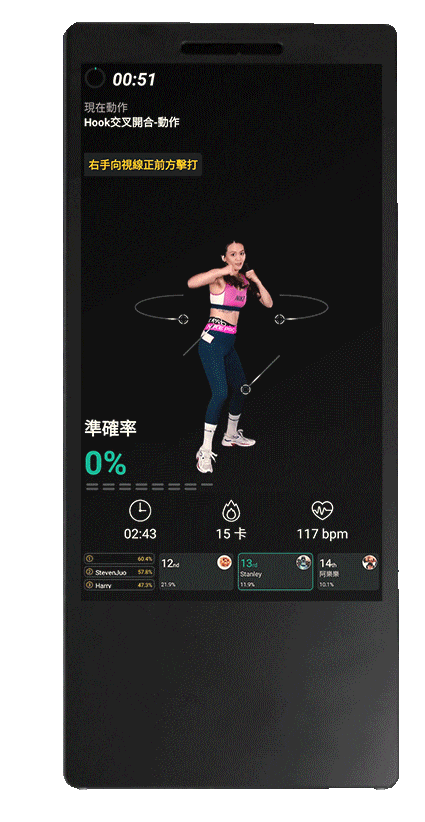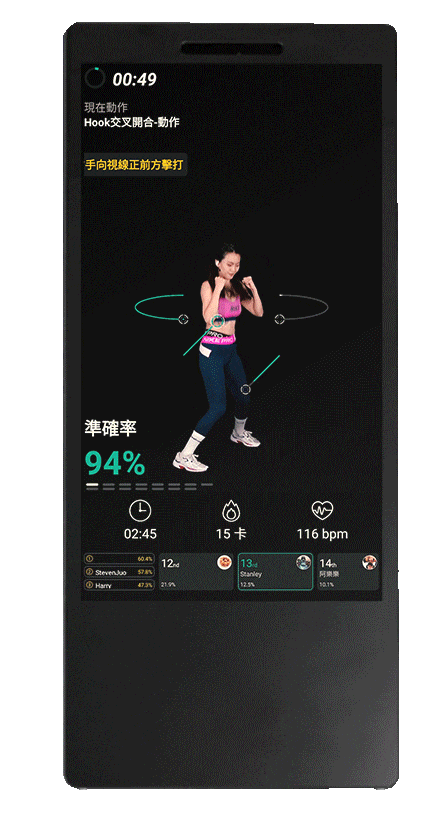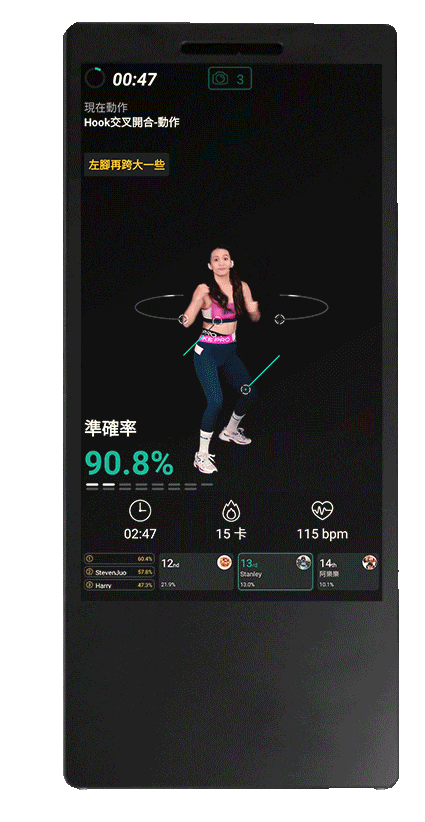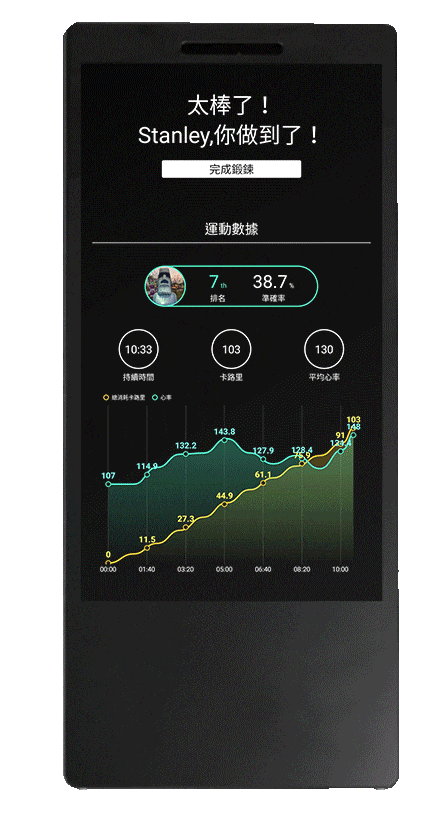
AI健身教練
健身新創 Peloton 在這波居家健身浪潮下,以販售主力產品飛輪、跑步機搭配線上課程,並將健身教練打造成「網紅」,用心拍攝運動影片,成功創造粉絲經濟。

- Pose-controlled Lights

- 跌倒偵測

 |
 |
-
產線SOP
以雅文塑膠來說,產線作業員的動作僅集中於上半身,以頭部、頸部、肩膀、手臂、手掌的動作為主。Beseye_alpha 針對需求,複製日本大型製造工廠 AI 模型開發的成功案例、及與客戶多次討論需求、實地作業工作站規劃、實際場域測試資料訓練,開發出一個「肢體律動分析」模型,有效達到降低運算量的目標。
Body Pose
Ref. A 2019 Guide to Huamn Pose Estimatioin
BodyPix - Person Segmentation in the Browser
Code: tfjs-models/body-pix
pip install tf_bodypix
Live Demo

OpenPose
Paper: arxiv.org/abs/1812.08008
Code: CMU-Perceptual-Computing-Lab/openpose
Ref. A Guide to OpenPose in 2021



PoseNet
PoseNet is built to run on lightweight devices such as the browser or mobile device where asOpenPose is much more accurate and meant to be ran on GPU powered systems. You can see the performance benchmarks below.
Paper: arxiv.org/abs/1505.07427
Code: rwightman/posenet-pytorch

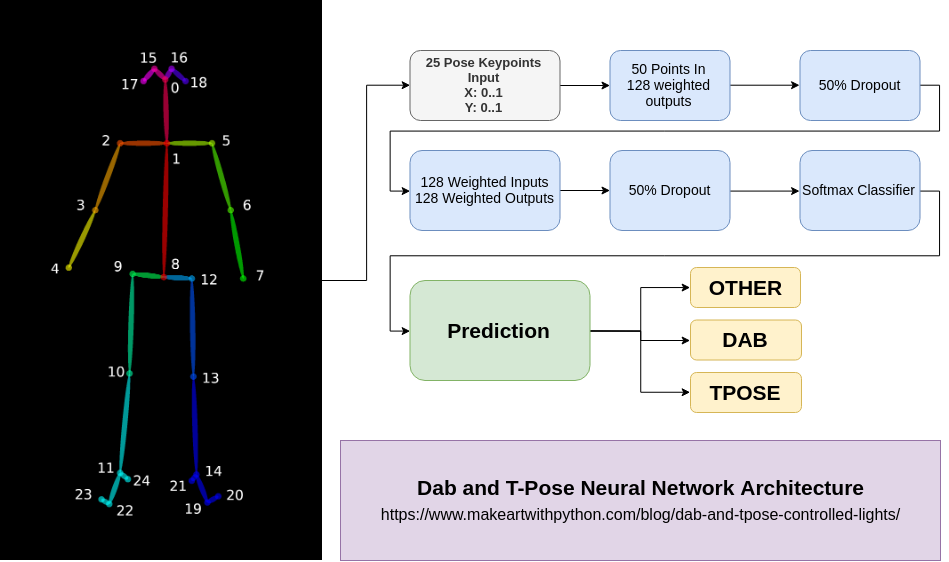
Pose Recognition
using Pose keypoints as dataset to train a DNN
Code: burningion/dab-and-tpose-controlled-lights
IPYNB: pose-control-lights

MMPose
Code: open-mmlab
Model Zoo
DensePose RCNN
Paper: arxiv.org/abs/1802.00434
Code: facebookresearch/DensePose
Region-based DensePose architecture

Multi-task cascaded architectures

Multi-Person Part Segmentation
Paper: arxiv.org/abs/1907.05193
Code: kevinlin311tw/CDCL-human-part-segmentation

Head Pose
Head Pose Estimation
Code:yinguobing/head-pose-estimation
 |
 |
Hopenet
Paper: Fine-Grained Head Pose Estimation Without Keypoints
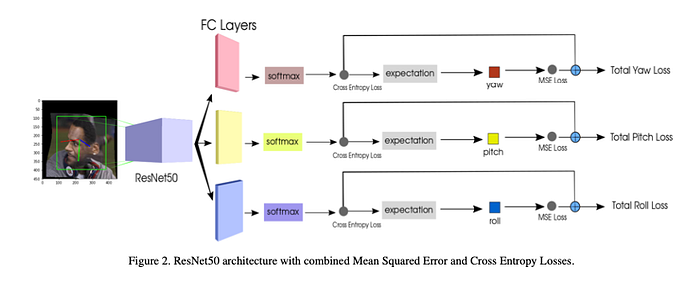
Code: deep-head-pose

Code: hopenet
Blog: HOPE-Net : A Machine Learning Model for Estimating Face Orientation
VTuber
Vtuber總數突破16000人,增速不緩一年增加3000人 依據日本數據調查分析公司 User Local 的報告,在該社最新的 User Local VTuber 排行榜上,有紀錄的 Vtuber 正式突破了 16,000 人。
1位 Gawr Gura(がうるぐら サメちゃん) Gawr Gura Ch. hololive-EN
2位 キズナアイ A.I.Channel
3位 Mori Calliope(森カリオペ) Mori Calliope Ch.
VTuber-Unity = Head-Pose-Estimation + Face-Alignment + GazeTracking**
VRoid Studio
VTuber_Unity

OpenVtuber
Hand Pose
Hand3D
Paper: arxiv.org/abs/1705.01389
Code: lmb-freiburg/hand3d

DeeHPS
Paper: arxiv.org/abs/1808.09208
GraphPoseGAN
Paper: arxiv.org/abs/1912.01875

3D Hand Shape
Paper: arxiv.org/abs/1903.00812
Code: https://github.com/3d-hand-shape/hand-graph-cnn
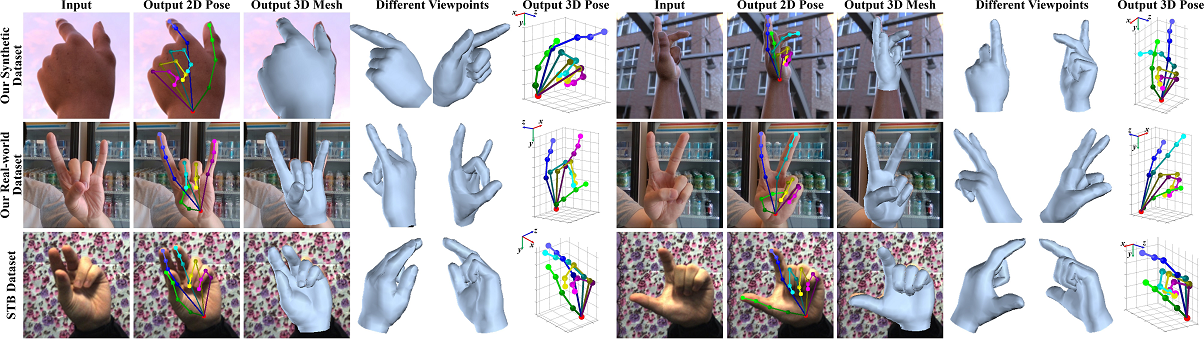
FaceBook InterHand2.6M
Paper: InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
Code: facebookresearch/InterHand2.6M

FrankMocap: Fast Monocular 3D Hand and Body Motion Capture by Regression and Integration
Paper: arxiv.org/abs/2008.08324
Code: facebookresearch/frankmocap


A Skeleton-Driven Neural Occupancy Representation for Articulated Hands
Paper: arxiv.org/abs/2109.11399

Towards unconstrained joint hand-object reconstruction from RGB videos
Paper: arxiv.org/abs/2108.07044
Code: hassony2/homan
 |
 |
 |
Fast Monocular Hand Pose Estimation on Embedded Systems
Paper: arxiv.org/abs/2102.07067
Recent Advances in 3D Object and Hand Pose Estimation
Paper: arxiv.org/abs/2006.05927
Object Pose
Benchmark for 6D Object Pose
Core datasets:
 |
 |
 |
 |
 |
 |
 |
| LM-O | T-LESS | TUD-L | IC-BIN | ITODD | HB | YCB-V |
Other datasets: LM, RU-APC, IC-MI, TYO-L.
Real-Time Seamless Single Shot 6D Object Pose Prediction (YOLO-6D)
Paper: arxiv.org/abs/1711.08848
Code: microsoft/singleshotpose
PoseCNN
Paper: arxiv.org/abs/1711.00199
Code: yuxng/PoseCNN

DeepIM
Paper: arxiv.org/abs/1804.00175
Code: liyi14/mx-DeepIM

Segmentation-driven Pose
Paper: arxiv.org/abs/1812.02541
Code: cvlab-epfl/segmentation-driven-pose
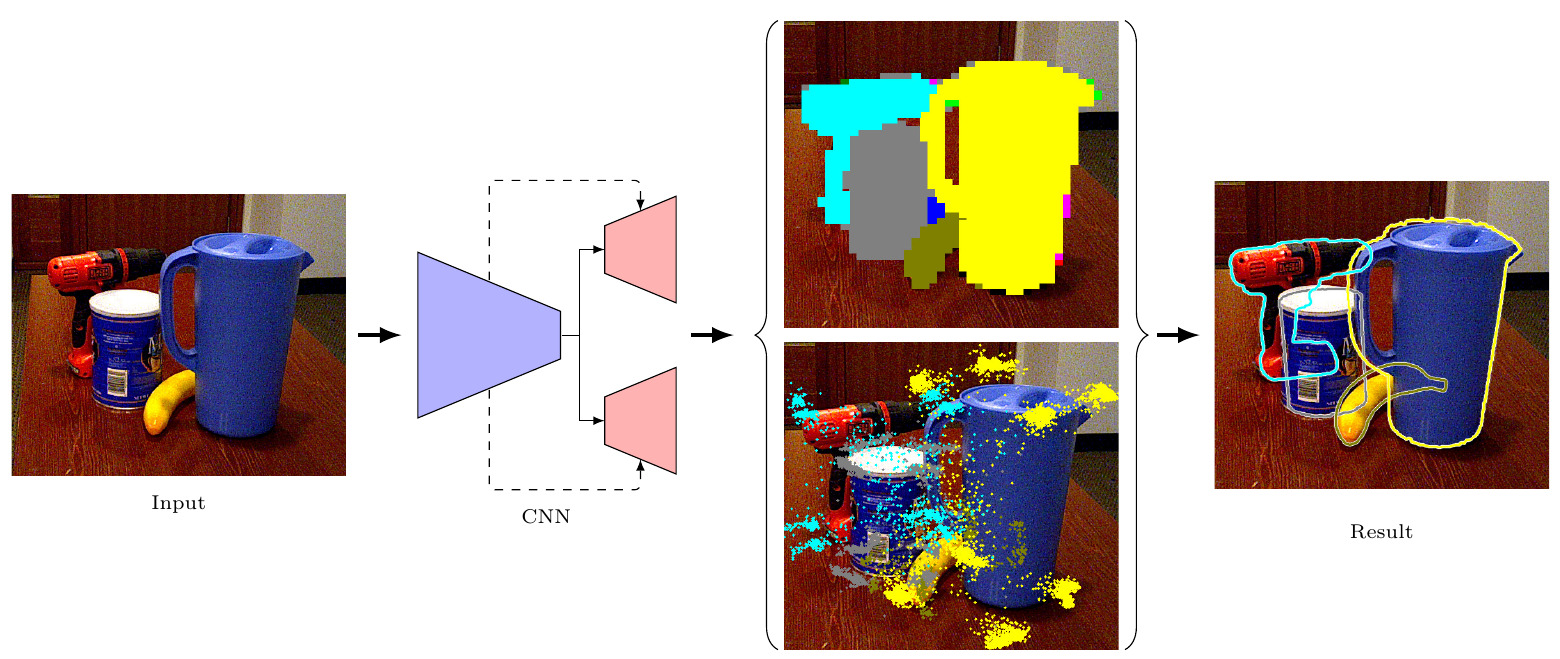
DPOD
Paper: arxiv.org/abs/1902.11020
Code: yashs97/DPOD
 |
 |

HO-3D_v3 Dataset
Paper: arxiv.org/abs/2107.00887
Github: shreyashampali/ho3d
HO-3D is a dataset with 3D pose annotations for hand and object under severe occlusions from each other.

Exercises of Pose Estimation
BodyPix
Kaggle: rkuo2000/BodyPix

PoseNet
Kaggle: rkuo2000/posenet-pytorch
 Kaggle: rkuo2000/posenet-human-pose
Kaggle: rkuo2000/posenet-human-pose

MMPose
Kaggle:rkuo2000/MMPose
2D Human Pose

2D Human Whole-Body

2D Hand Pose

2D Face Keypoints

3D Human Pose

2D Pose Tracking

2D Animal Pose

3D Hand Pose

WebCam Effect

OpenPose
Kaggle: rkuo2000/openpose-pytorch


Pose Recognition (姿態辨識)
專題實作步驟:
- 建立身體動作之姿態照片資料集 (例如:5 poses , take 20 pictures of each pose)
- 始用MMPose 辨識出照片中的各姿勢之身體關鍵點 (use MMPose convert 16 keypoints (x,y) of each pose)
- 產生姿態關鍵點資料集 x_train.append(pose_keypoints) ( x_train.shape = (20x5, 16, 2), y_train.shape= (20x5, 1) )
- 建立DNN模型並訓練模型, 然後下載模型檔
pose_dnn.h5至PC - 於PC建立帶camera輸入之服務器程式, 載入模型
pose_dnn.h5進行姿態動作辨識
模型建構與訓練之程式樣本 (PC or Kaggle)
input_shape=(16,2)
num_classes=5
inputs = layers.Input(shape=input_shape)
x = layers.Dense(128)(inputs)
outputs = layers.Dense(num_classes, activation="softmax")(x)
model = models.Model(inputs=inputs, outputs=outputs)
models.compile(loss = 'categorical_crossentropy', optimizer = 'adam' , metrics = ['accuracy'])
history = model.fit(x_train, y_train, batch_size=1, epochs=20, validation_data=(x_test, y_test))
models.save_model(model, 'pose_dnn.h5')
姿態辨識服務器之程式樣本 (PC with Camera)
model = models.load_model('models/pose_dnn.h5')
labels = ['stand', 'raise-right-arm', 'raise-left-arm', 'cross arms','both-arms-left']
cap = cv2.VideoCapture(0)
while(cap.isOpened()):
ret, frame = cap.read()
image = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
mmdet_results = inference_detector(det_model, image) # 人物偵測產生BBox
person_results = process_mmdet_results(mmdet_results, args.det_cat_id) # 記住人物之BBox
pose_results, returned_outputs = inference_top_down_pose_model(...) # 感測姿態產生pose keypoints
x_test = np.array(preson_results).reshape(1,16,2) # 將Keypoints List 轉成 numpy Array
preds = model.fit(x_test) # 辨識姿態動作
maxindex = int(np.argmax(preds))
txt = labels[maxindex]
print(txt)
Head Pose Estimation
Kaggle: rkuo2000/head-pose-estimation
VTuber-Unity
Head-Pose-Estimation + Face-Alignment + GazeTracking
Build-up Steps:
- Create a character: VRoid Studio
- Synchronize the face: VTuber_Unity
- Take video: OBS Studio
- Post-processing:
- Auto-subtitle: Autosub
- Auto-subtitle in live stream: Unity_live_caption
- Encode the subtitle into video: 小丸工具箱
- Upload: YouTube
- [Optional] Install CUDA & CuDNN to enable GPU acceleration
- To Run
$git clone https://github.com/kwea123/VTuber_Unity
$python demo.py --debug --cpu
OpenVtuber
Build-up Steps:
- Repro Github
$git clone https://github.com/1996scarlet/OpenVtuber
$cd OpenVtuber
$pip3 install –r requirements.txt - Install node.js for Windows
- run Socket-IO Server
$cd NodeServer
$npm install express socket.io
$node. index.js - Open a browser at http://127.0.0.1:6789/kizuna
- PythonClient with Webcam
$cd ../PythonClient
$python3 vtuber_link_start.py
Hand Pose
Dataset: InterHand2.6M
- Download pre-trained InterNet from here
- Put the model at
demofolder - Go to
demofolder and editbboxin here - run
python demo.py --gpu 0 --test_epoch 20 - You can see
result_2D.jpgand 3D viewer.
Camera positios visualization demo
cd tool/camera_visualize- Run
python camera_visualize.py
This site was last updated December 22, 2022.